In my previous post about AMHR filter I told you that the filter was taking care of the sensors error by being robust to linearity and bias error of our LSM9DS1 chip. Indeed, the Madgwick’s filter is robust against them, but minoring theses error can still be usefull because it will take less time at startup to converge to the correct orientation and it will help getting a more accurate estimation of the speed and the position of the robot.
Good news is that it is possible to perform a calibration to lower the error as some of them are due to factory issued and will be constant for a given chip. Bad news is that it is not possible to completely remove them because some part are temperature dependant and will be drifting over time.
Calibration involve running a certain number of measurements based on known conditions and based on the measurements, compute a correctionto be applied on sensor output. This will present the method I used to perform the accelerometer calibration but it can be used also for the magnetometer.
With a perfect accelerometer in a perfect robot mechanic standing on a perfect floor, the read out of the accelerometer should be
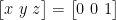
Of course in a real world, the sensor is not perfect and for each axis, it shows a linearity and a bias error.
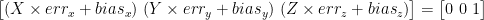
where 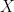
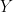
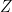


Our goal will be to determine the 6 unknown from the previous equation.
Let’s imagine that we have a perfect rig available so we can position our robot in six perfectly known positions. We can choose theses position so the gravity vector is aligned with each axis in both direction. During the calibration we just measure the output of the sensor for each orientation and we just have to solve this equation system:

Unfortunatly, I don’t have any calibrated rig available to do the measurement so it will make our life harder as we don’t known the direction of the gravity vector. However, whatever it’s direction, we still know that it’s norm is equal to 1g. So we can pose if the robot is standing still:

Which can be simplified as:

So to acheive our calibration process, we just have to find the roots of the following equation system:

Unfortunalty, that’s not so easy to solve because this equation system is not linear (some square unknown appear in the calculation).
That’s where Newton and his buddy Raphson come to save the day as they developped an algorithm which is going to be a great help in our case. The Newton Raphson method is a method to find an approximation of the root of a function by iteration.
The idea, is simple. Start with a value of your function that you know is close to the solution. Calculate the derivate of the function for this point (which is the tangent line at this point) and determine when this tangent equals 0. Then use this value as the new starting value and repeat the operation until you reach the needed precision.

In other word for a single equation:

This method can be extended to solve system of non linear equation but it gets a little bit more complex. In that case instead of dividing by 

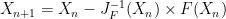
A jacobian matrix is a matrix containing the first order partial derivates for each of our function.

So we only have to perform the partial derivate of

On 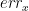

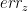



The process of calculating a partial derivate is easy. Derivate according to one unknown and treat the other as constant. For example if we want to calculate the partial derivate of 


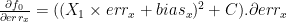

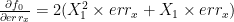
The same way we can show that
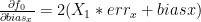
We can extrapolate our jacobian matrix for our functions:
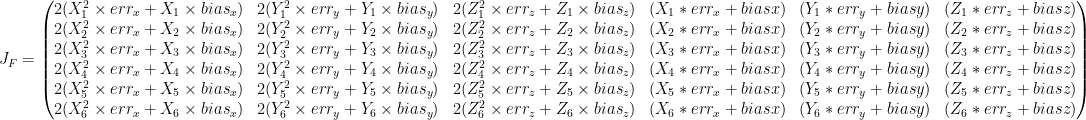
That’s a big matrix, but at the end, it is only the two same easy computation repeated each 3 times.
However we are not done yet, as Newton algorithm asks us to invert this matrix but it can be very time consuming to do so. So we can change this:
to look like this:
And solve this equation system with 

This time this system is linear and you may have notice that it is in the form of 
Fortunatly for us, we won’t have to do it ourself (that’s way too many math already! ) as a nice library called Eigen is offering to do the job for us. This library is completly template based so we just have to include the header in our code and solving this equation is as simple as:
MatrixXd Xd = jacobian.lu().solve(-F);
And we are done ! We just have to repeat the process until we reach the precision we want.
So finally how is the code looking ? very simple compared to the rest of this article 🙂
double CSensorCalibration::partialDerivateOffset (double val, double offset, double scale)
{
double ret = 2.0 * (val * scale + offset);
return ret;
}
double CSensorCalibration::partialDerivateScale (double val, double offset, double scale)
{
double ret = 2.0 * (val * val * scale + val * offset);
return ret;
}
MatrixXd CSensorCalibration::solve (MatrixXd & Meas)
{
MatrixXd jacobian(6,6);
MatrixXd X(6,1);
MatrixXd F(6,1);
int32_t iter;
//Init solution
X << 0.0, 0.0, 0.0, 1.0, 1.0, 1.0;
for (iter = 0; iter < MAX_ITERATION; iter++)
{
//Calculate jacobian matrix
for (int i = 0; i < 6; i++)
{
for (int k = 0; k < 3; k++)
{
jacobian(i,k) = partialDerivateOffset(Meas(i,k),X(k,0),X(3+k,0));
jacobian(i,3+k) = partialDerivateScale(Meas(i,k),X(k,0),X(3+k,0));
}
}
//Compute "result" matrix.
for (int i = 0; i < 6; i++)
{
F(i,0) = pow(Meas(i,0)*X(3,0) + X(0,0), 2) + pow(Meas(i,1)*X(4,0) + X(1,0), 2) + pow(Meas(i,2)*X(5,0) + X(2,0), 2) - 1;
}
//Check if we reached our precision requierement.
if (abs(F.sum()) <= LIMIT_CONV_FUNCT)
{
break;
}
//Solve J_F(x_n)(x_{n+1} - x_n) = -F(x_n)
MatrixXd Xd = jacobian.lu().solve(-F);
//Check if we reached our precision requierement.
if (abs(Xd.sum()) <= LIMIT_CONV_ROOT)
{
break;
}
//Update our result as the equation is giving us the (x_{n+1} - x_n).
X = X + Xd;
}
return X;
}